Time2graph: Revisiting time series modeling with dynamic shapelets
Shapelet 1 是一种常见的对时序数据进行建模的方法之一。从 2009 年在 KDD 上发布第一篇论文以来,其经过了各式各样的变形和改进。Time2graph 2 观察到 shapelet 具有 time-aware 的性质,因此提出了一种基于 shapelet 的时序数据的建模方法,将数据建模成图结构。
What #
Shapelet #
A shapelet is a segment that is representative of a certain class. Shapelet 是一段具有代表性的子序列,它可以将一条时序数据的所有分段分成两类,一类与其相似,另一类与其不同。
Time-aware shapelet #
Time2graph 中所创新性提出的包含时间信息的 shapelet,利用图对其在时间维度上的变化进行捕捉。
Why #
传统的 shaplet 以及其改进形式都忽略了 shapelet 在不同的时间区间上的表现能力。这造成两点不足:
- 相同 shapelet 在不同时间区间上的含义不同。
- shapelet 之间的变化关系也表示了时序数据的一些信息。
How #
Time-Aware Shapelet Extraction #
Time-aware shapelet 的抽取可以分为以下三个步骤
分段
这里需要超参数如:每个分段的长度
选取 Candidate
这一部分在论文中没有叙述,但阅读源代码后,我们可以发现,针对所有分段后得到的片段,有两种方法从中得到 candidate shapelet。第一种是通过聚类,例如 K-Means,和 DTW 作为距离进行聚类,然后选取类中心的片段作为 candidate。第二种则是贪婪的方法,即遍历计算一个片段与其他所有片段之间的距离,然后选取平均最小的片段作为 candidate。
计算评分
Time2graph 设计了新的评分方法来衡量 shapelet 在时间维度上的重要度,这部分比较复杂,后文会进行详细的介绍。对所有的 shapelet candidate 打分后,我们就可以选取 top-k 作为真正的 shapelet。
Distance #
Time2graph 设计了两个需要训练的参数,local factor w 和 global factor u 来分别衡量 shapelet 内部每个元素的重要度以及 shapelet 在不同时间段上的重要度。
训练的过程需要进行梯度下降,损失函数如下图所示
v: shapelet
T: time series
S∗(v, T): the set of distances with respect to a specific group T∗
g: differentiable function measures the distances between distributions of two finite sets
最后两项为 penalties。当梯度下降使得损失函数的值越来越小时,w 和 u 就越来越可以使得 shapelet 到 positive 和 negative 的距离之差越来越大,这样 shapelet 就越能代表一个类。
接下来,详细介绍损失函数中所用到的两个距离函数。
- shapelet 与 segment 之间的距离
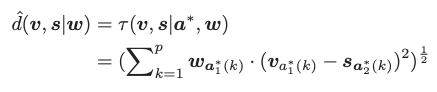
w: local factor 需要学习的参数
u: global factor 需要学习的参数
s: segment
a: alignment,利用 DTW 可将长度为 i 的 v 和长度为 j 的 s 对齐成长度为 p 的 a1 和 a2
对于 DTW alignment,下面这张图形象地解释了整个对齐的过程
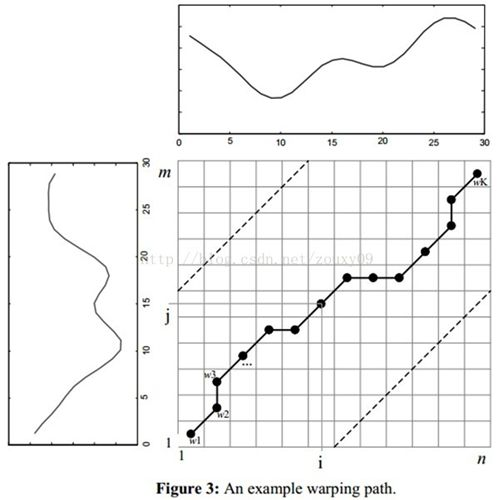
对于序列 s1 和 s2,s1 中的一个点可能对应 s2 中的多个点,同时 s2 中的一个点也可能对应 s1 中的多个点。所以,两者对齐后,会得到一个新的长度的序列。而 shapelet 与 segment 的距离,其实就是计算两者对齐后的欧氏距离。
- shapelet 与 time series 之间的距离
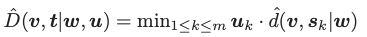
这个就比较简单了,d 即为刚刚介绍的 shapelet 与 segment 之间的距离。shapelet 与 time series 的距离即为与 time series 的所有分段中的权重最小值。
Shapelet Evolution Graph #
接下来,就是要构建图来表示 shapelet 之间的转移关系。
算法先将 shapelet 与 segment 关联起来,edge 的权重由以下这个公式计算
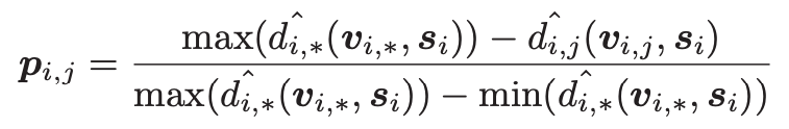
公式计算的是 shapelet 与 segment 相关的概率,如果 shapelet 与 segment 之间的距离越近,那么相关的概率越高。
接下来,算法将相邻的 segment 的 shapelet 连接起来,而 edge 的权重则是前后两个 segment 与各自 shapelet 之间关联概率的乘积,代表了从前一个 shapelet 迁移到后一个 shapelet 的概率。
![]()
最后,算法将一个 shapelet 所有迁移出去的 edge 的权重进行归一化,使其和为 1。
算法的伪代码如下所示

Representation Learning #
最后,time2graph 采用了 DeepWalk 3的算法,将 shapelet 转换为 embedding 的形式。
接下来,就可以利用 shapelet 的 embedding 来表示 segment 和 time series。
segment 的向量化表示如下面这个公式,就是其相关 shapelet 的 embedding 的概率权重和

而 time series 的向量化表示就是将其所有 segment 的 embedding 的拼接。
算法的伪代码如下所示

Apply Time2graph #
至此,我们就完整的了解了 time2graph 的训练过程。那么 time2graph 的应用过程也与之类似。
首先,算法的输入仍然是一个 time series。算法会先对其进行分段,然后为每个 segment 分配相关的 shapelet。接下来,就可以得到 segment 和 time series 的 embedding,进行后续聚类或者其他操作。